Multi-Sentence Grounding for Long-term Instructional Video
|
1Coop. Medianet Innovation Center, Shanghai Jiao Tong
University
|
|
2Shanghai AI Laboratory, China
|
3Visual Geometry Group, University of Oxford
|
Abstract
In this paper, we aim to establish an automatic, scalable pipeline for denoising the large-scale instructional
dataset and construct a high-quality video-text dataset,
named HowToStep. We make the following contributions:
(i) we improve the quality of textual narration by upgrading
ASR systems, i.e., to reduce errors from speech recognition,
and later transform noisy ASR transcripts into descriptive
steps by prompting a large language model; (ii) we propose
a Transformer-based architecture with all texts as queries,
iteratively attending to the visual features, to temporally
align the descriptive texts to corresponding video segments.
(iii) to measure the quality of our curated datasets, we train
models for the task of multi-sentence grounding on it, i.e.,
given a long-term video, and associated multiple sentences,
our goal is to determine the corresponding timestamps for
all sentences in the video, as a result, our model demonstrates superior performance on multi-sentence grounding
tasks, surpassing existing state-of-the-art methods by a significant margin on three public benchmarks, namely, 9.0%
on HT-Step, 5.1% on HTM-Align and 1.9% on CrossTask.
All codes, models, and the resulting dataset will be publicly
released to the research community.
Architecture
Schematic visualization of the proposed Transformer-based video-text alignment network termed NaSVA.
The visual features are treated as key-value pairs while textual features are treated as queries, to predict the alignment score matrix between video frames and texts.
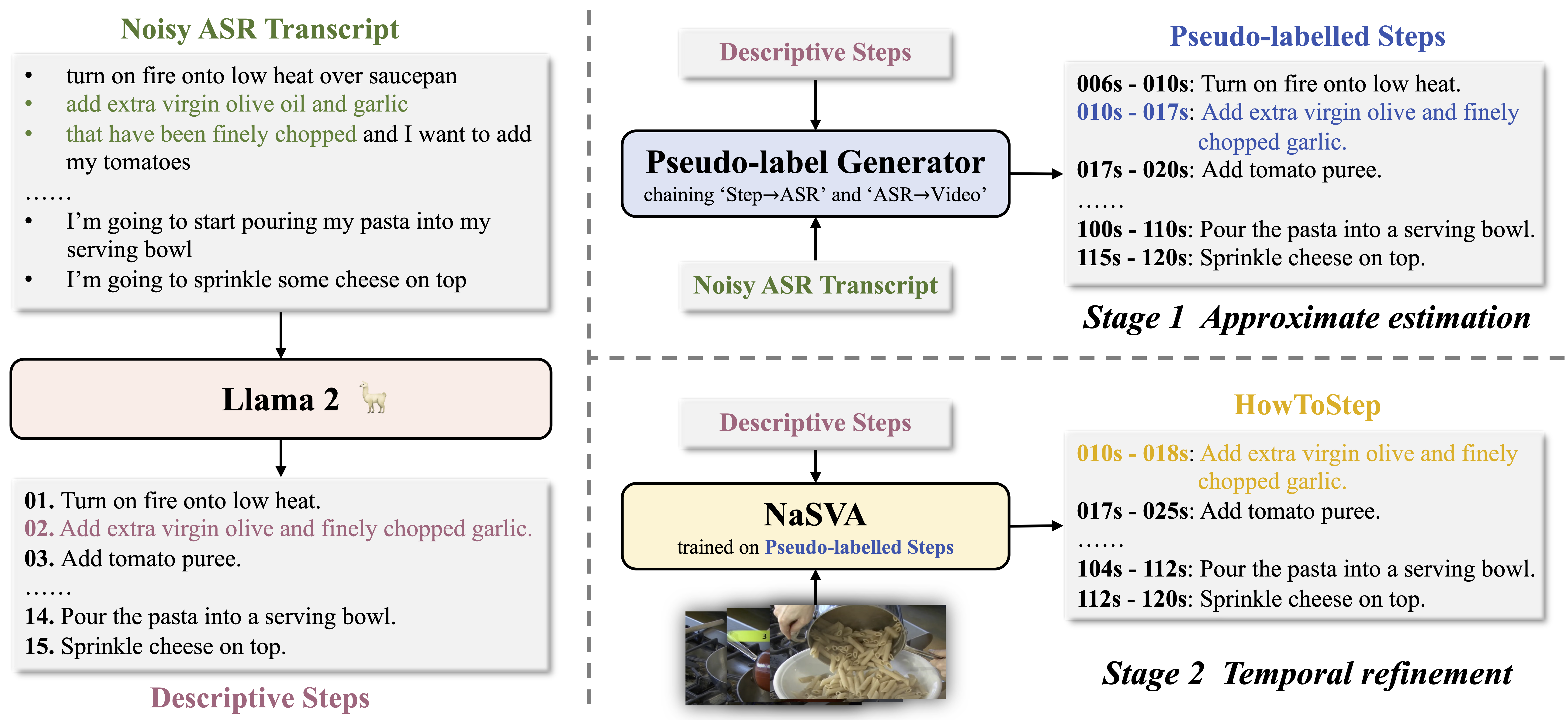
ASR Transcripts → Aligned Descriptive Steps
As presented in the following figure,
the entire procedure of ASR transcripts transformation can be divided into three parts:
(i) we leverage LLM to summarize narrations from the ASR transcript into descriptive steps; (ii) we use the similarity between the original transcript and generated steps to roughly determine the start/end timestamp for each step as pseudo-label;
(iii) we train the NaSVA model on the generated steps with pseudo-label, and then use the trained model to refine the time range for each generated step (i.e., self-training).
We name the final dataset as HowToStep.
Results
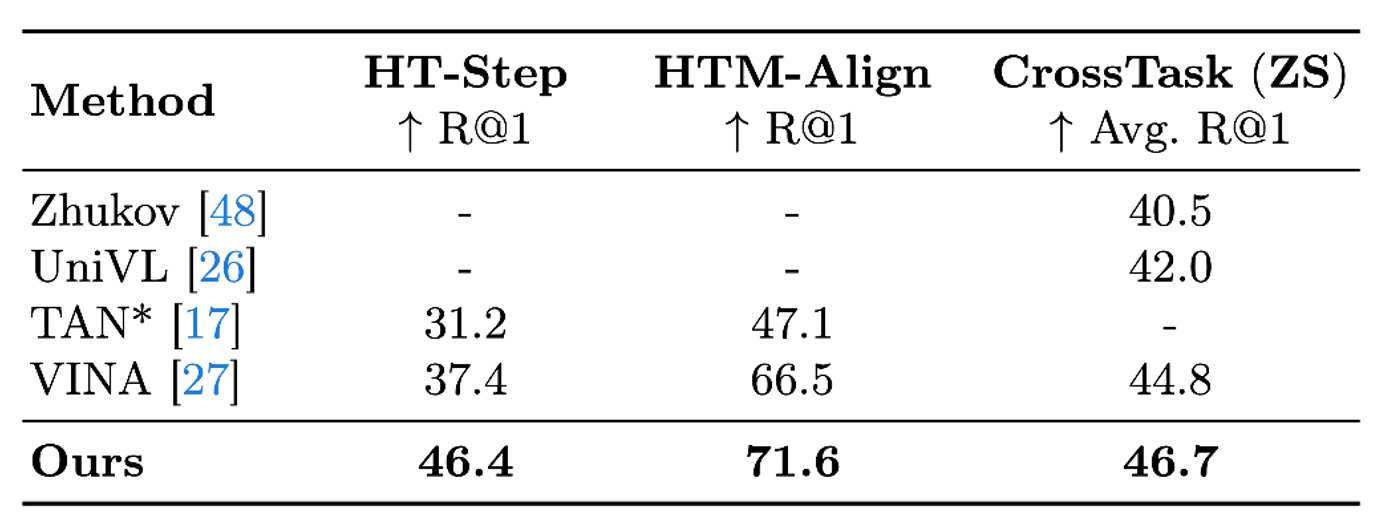
We compare our best model with existing state-of-the-art approaches on three public benchmarks for multi-sentence grounding tasks.
As shown in the table, on the challenging HT-Step task,
that aims to ground unordered procedural steps in videos,
our model achieves 46.4% R@1, leading to an absolute improvement of 9.0%, over the existing state-of-the-art (37.4%) achieved by VINA.
On HTM-Align, which aligns narrations in the video,
our method exceeds the SOTA model by 5.1%.
On CrossTask, where we need to align video frames and task-specific steps without finetuning, our method outperforms existing the state-of-the-art approach by 1.9%,
demonstrating the effectiveness of the proposed pipeline for downstream grounding tasks.
Acknowledgements
Based on a template by Phillip Isola and Richard Zhang.
