|
I am a second-year PhD candidate at Shanghai Jiao Tong University (SJTU), advised by Prof. Weidi Xie. I received my Bachelor degree in Information Engineering, also from Shanghai Jiao Tong University. My research focuses on long video understanding and multi-modal representation learning. |

|
|
|
|
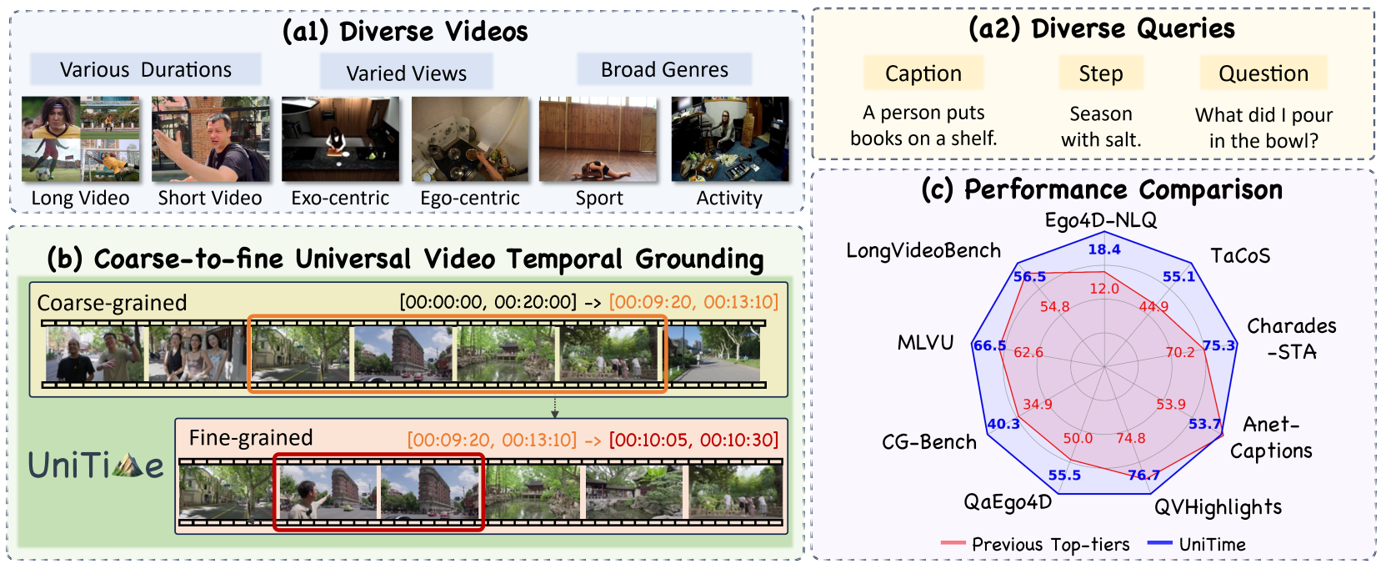
Zeqian Li, Shangzhe Di, Zhonghua Zhai, Weilin Huang, Yanfeng Wang, Weidi Xie NeurIPS, 2025 paper / project page / code Towards universal video grounding with superior accuracy, generalizability, and robustness. |

|
Yibin Yan*, Jilan Xu*, Shangzhe Di, Yikun Liu, Yudi Shi, Qirui Chen, Zeqian Li, Yifei Huang, Weidi Xie ICCV, 2025 paper / project page / code Learn streaming video representations of various granularities through multitask training, including retrieval, action recognition, temporal grounding, and segmentation. |
|
Zeqian Li*, Qirui Chen*, Tengda Han, Ya Zhang, Yanfeng Wang, Weidi Xie ECCV, 2024 paper / project page / code An automatic, scalable pipeline for denoising the large-scale instructional dataset and construct a high-quality video-text dataset with multiple descriptive steps supervision. |
|
|